WeiboEvents 的设计与实现
January 11, 2014

WeiboEvents 是在大三下学期时,也就是 2012 年初开始设计的。上完袁老师的可视化课程之后,对这个领域有了一定兴趣,就加入实验室和张昕师兄、王臻皇和李菁一起做微博可视化。这个工具主要功能就是对单条微博的转发树进行可视分析。一条微博及其所有转发构成一个转发树,我们成之为事件 (Event),WeiboEvent 这个名称就是由此而来。对转发树的分析可以了解到其中的主要参与者、用户的行为模式,以及是否有人为干预等等,从而对事件有更深入的理解。
这大概是我做过的最有影响力的一个项目了吧。从今年 9 月改版以来到写这篇文章的时候,有 15000 次使用记录,2500 个用户。 从最初发布到现在,这个工具已经积累了 3000 个微博事件可视化作品,其中有一部分还是很有价值的(具体参见这里)。最近在 PacificVis 会议上发表了 Visualization Notes:
- WeiboEvents: A Crowd Sourcing Weibo Visual Analytic System Proceedings of IEEE Pacific Visualization Symposium (PacificVis 2014) Notes, 330-334, 2014 PDF doi:10.1109/PacificVis.2014.38
这篇文章简单地对积累下来的可视化作品进行一下总结,然后主要从实现的角度讲一讲这个工具的故事。大概会回答下面几个问题:
- 微博事件大概有哪些模式?
- 如何利用 HTML5 技术设计这样的一个工具?
- 如何抓取微博数据?
这只是一篇日志,也不可能写得很具体,就当是一些心得吧。好久没有更新过这个博客了,也想练习一下写作了 :) 今后会时不时地写点什么~
微博传播模式分类
关于这个话题的研究已经很多了。我对这方面的了解也不多,但很高兴能看到有利用 WeiboEvents 进行分析的文章,比如下面这篇:
作为工具的设计者,我们似乎也要进行一定程度上的分析,虽然没有传播学研究者那么专业,但对于微博事件的分类还是可以给出一些结论的。
首先介绍一下 WeiboEvents 中四种转发树的表示方法,如下图:
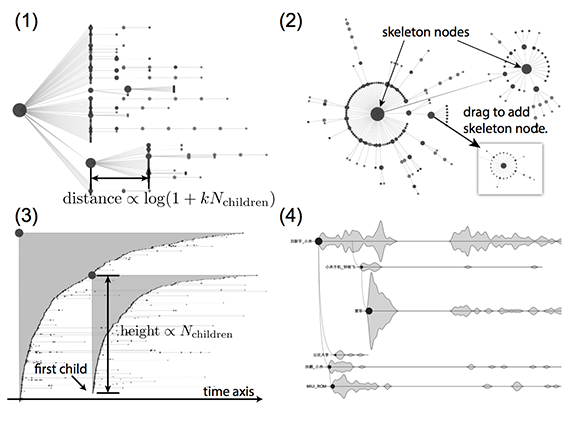
- 树状视图:最直观的树形视图,显示转发结构。
- 圆环视图:根据转发量选取一些重要节点,把它们每个画成圆环的形状,较小的节点分布在圆环的周围。
- 帆状视图:横轴表示时间,把一条微博的所有转发画成帆的样子,帆的高度由转发量决定。这个视图可以直观地看到转发随时间的变化。
- 时间线视图:与圆环视图类似,也根据转发量选取一些重要节点,每个节点和它的转发画成一条随时间变化的曲线。这个视图中不能看到单个节点,但可以直观地比较重要节点转发的时间模式。
这四种方法各有优缺点,分析时应该综合利用。
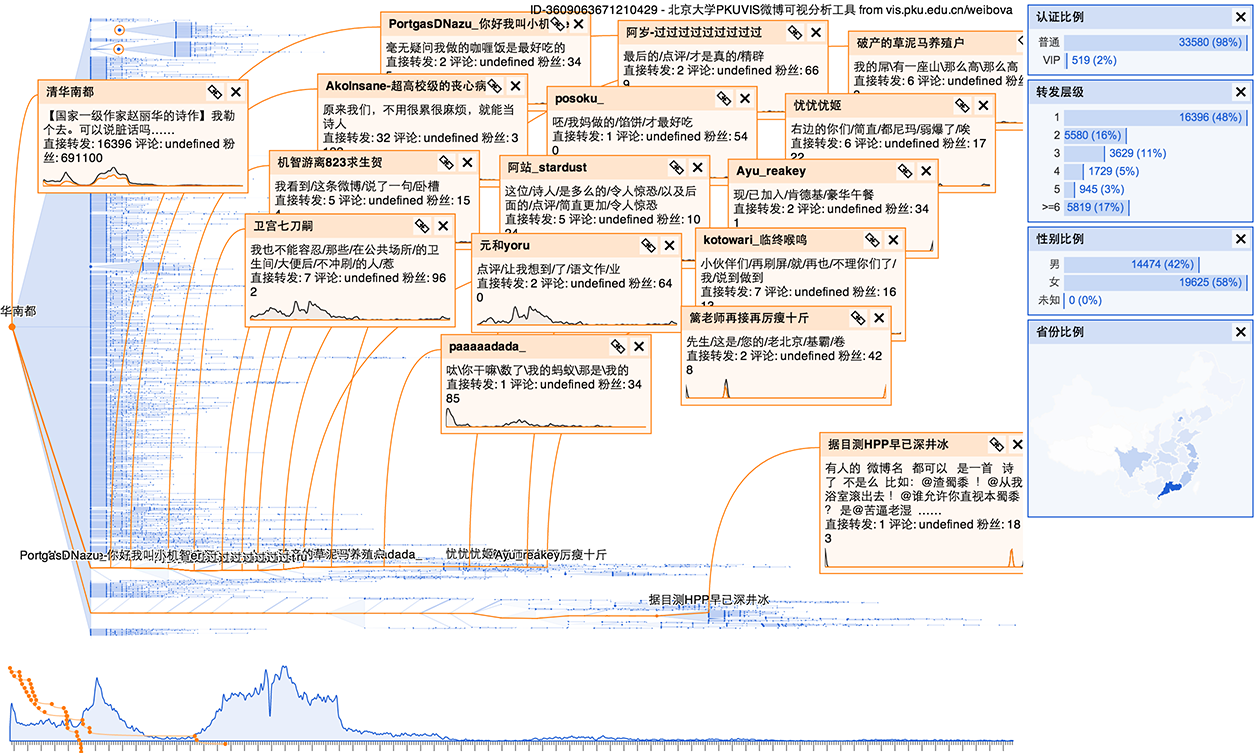
涉及虚假用户的事件
虚假用户一般是由一些机器账户,它们听从所有者的控制,可以用来增加转发量,使得某个事件看上去很有影响力。 这种传播的特征是时间上的模式非常明显。例如下图:
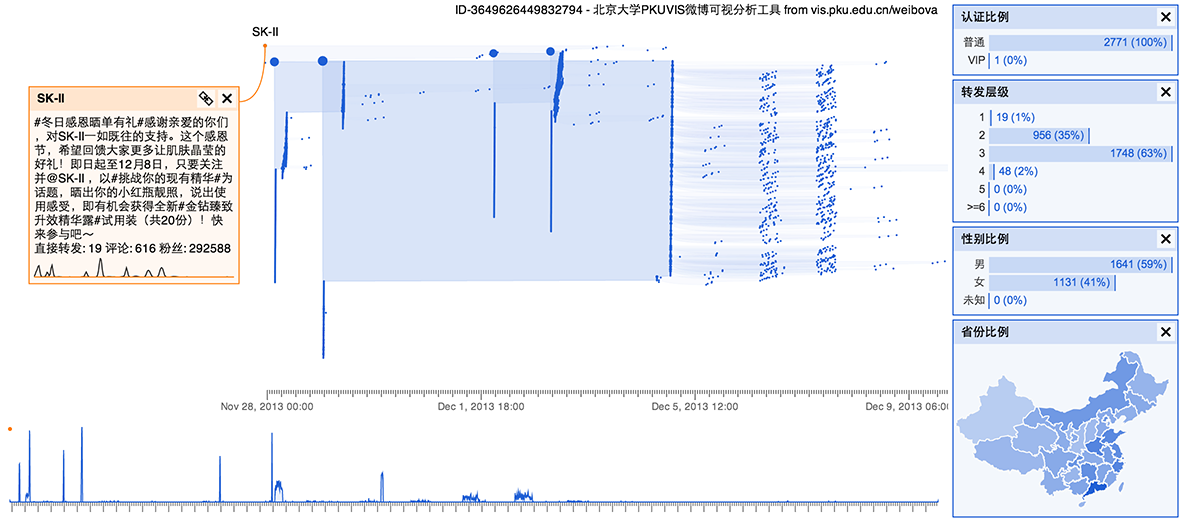
可以看出人为痕迹非常明显,这样的事件一般具有下面几个可能的特征:
- 转发速度恒定:因为机器是按照某个固定频率发送微博的。正常的事件,由于受众逐渐饱和,转发速度会随时间明显下降。
- 转发时间集中,或者中间有明显间歇:这也是机器账户的特点,不同的机器有不同的策略,从而看上去彼此不同,但都和正常的事件有明显的区别。
- 省份分布均匀:左右两个事件中的用户的省份分布非常均匀,正常的事件不大可能出现这种情况,因为人口分布、事件发生地点等很多原因,不可能分布得非常均匀。
- 转发层级较浅:机器账户一般不会刻意去制造非常长的转发链。
自然的扩散
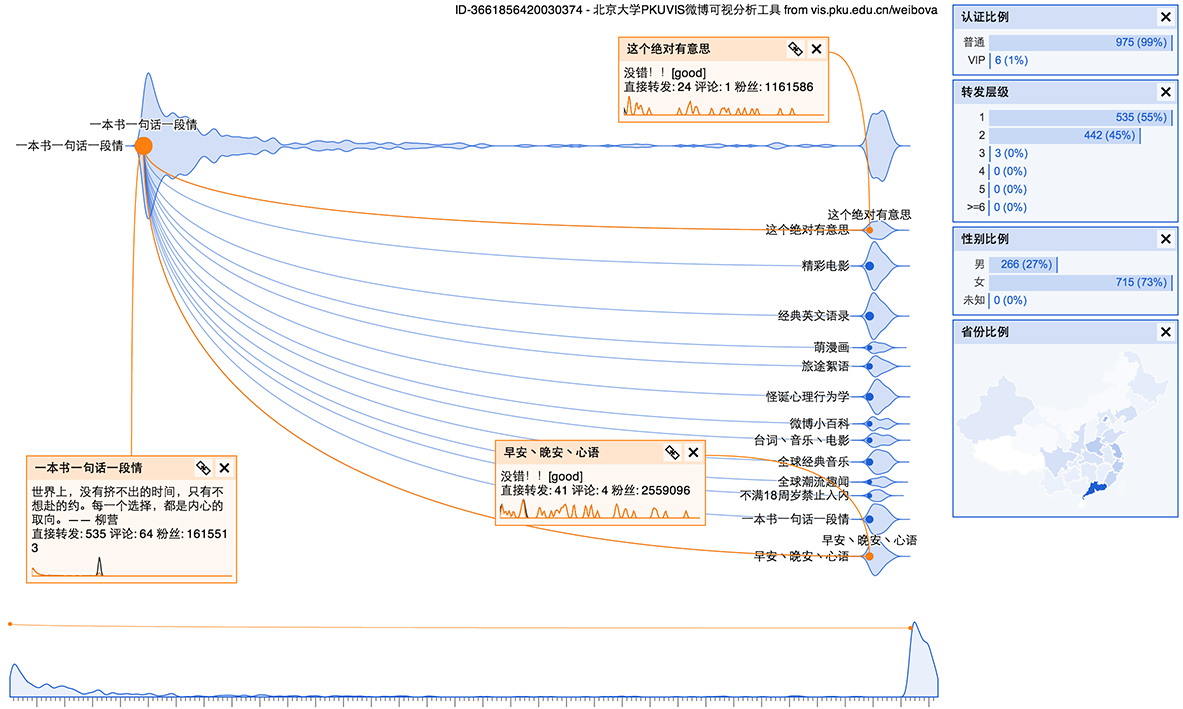
下面图中展示一个正常传播的事件。其中包含 13 万条微博。传播速度很快,大部分是真实账户。
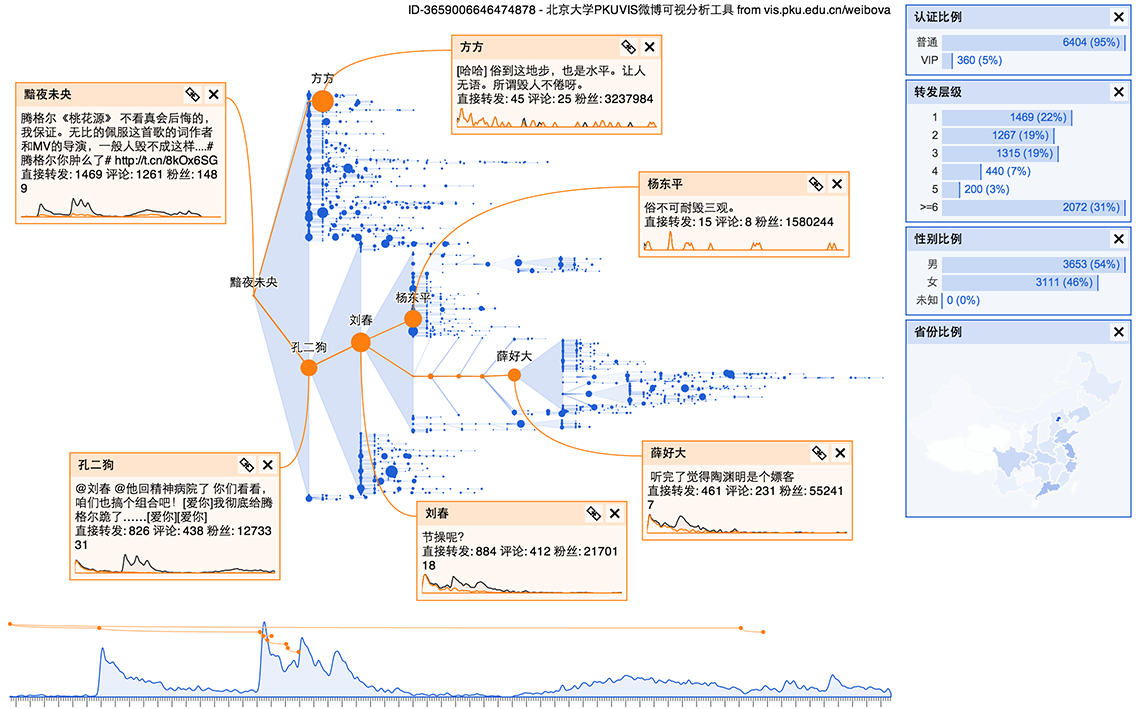
这样的事件有下面一些特点:
- 转发层级很多:除了公共账户的影响,通过朋友关系传播也很重要。
- 转发树有一种自相似的结构:每个人转发后都可能导致朋友的转发,直到整个网络饱和。
- 省份分布比较符合预期:对于全国范围的事件,大致和微博用户的人口分布相同。
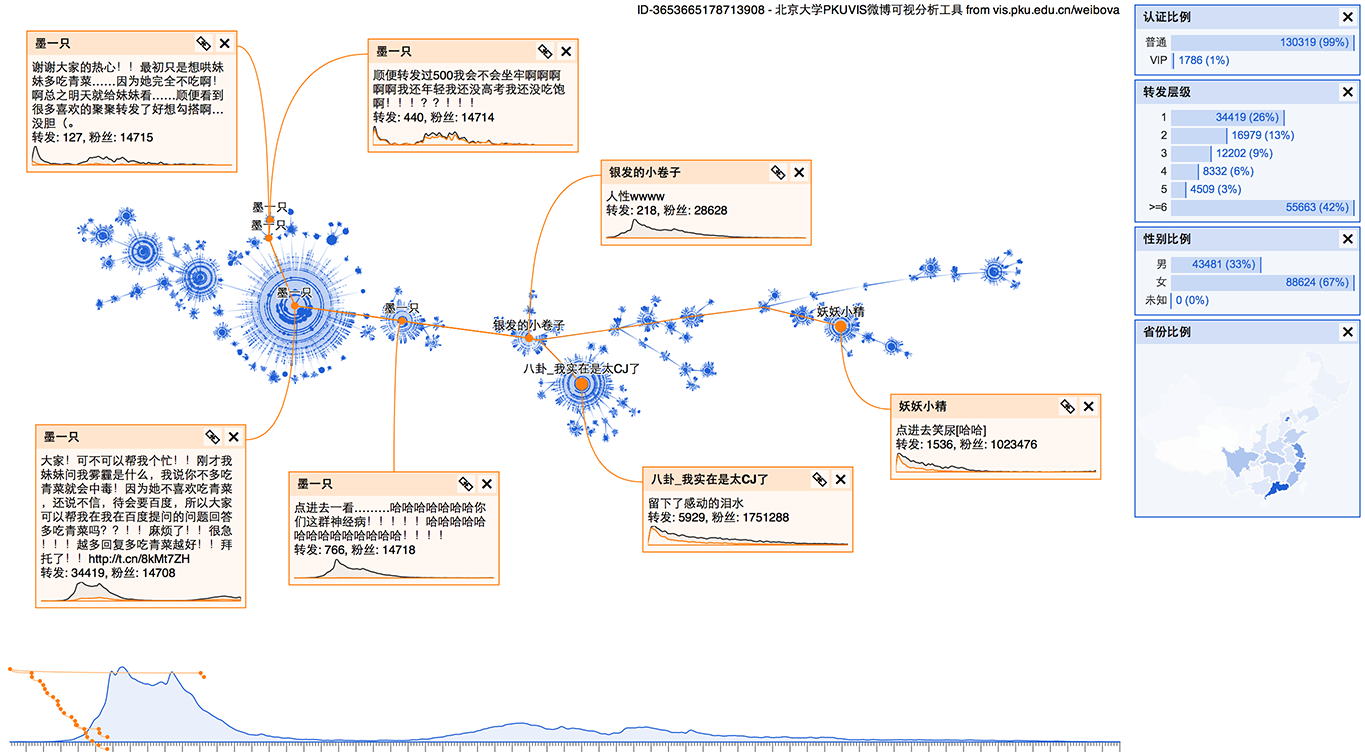
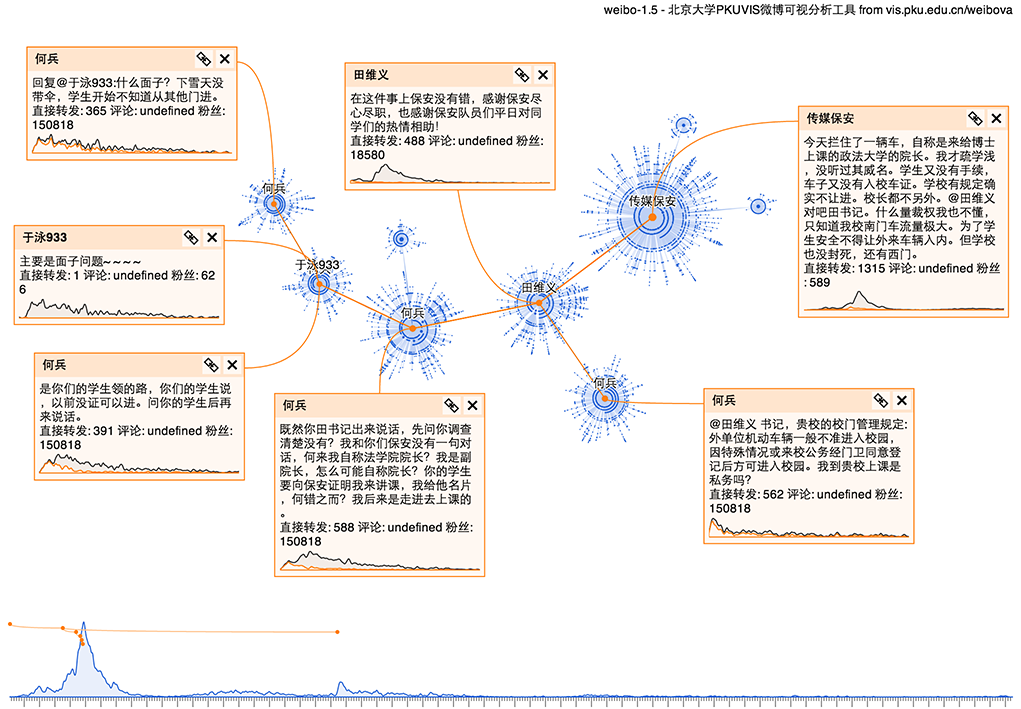
有故事性的事件
还有一些事件比较复杂,不光是自然传播,而是有一定的结构,例如下面传媒大学保安事件中,是围绕某个问题进行争论,而这场争论被公众关注,因此每条争论的微博都有一定的转发量。
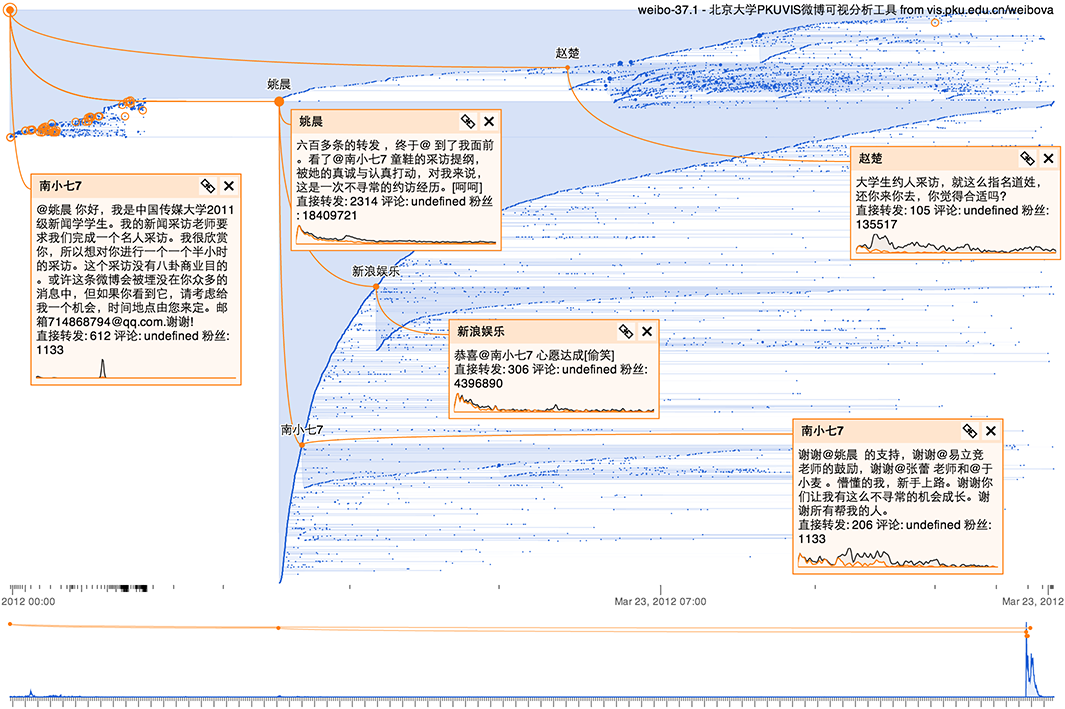
而下面这个“传媒大学学生约访姚晨”事件没有争论,但在时间上很有趣,显示南小七发布了约访姚晨的微博,起初转发量不大,但一段时间以后,姚晨看到了这条微博(或许是通过社交网络转发到了姚晨的圈子里),从而带来了巨大的转发量。
事件的整体统计
这里考察所有用户分析过并保存分析结果的事件。可以获得正确数据并得到特征的总共有 1300 个左右。下面三张图展示所有微博事件的转发层级、粉丝数、关注数所占的比例。这三张图的横轴是转发层级、粉丝数、关注数,纵轴表示微博所占的比例。图表由很多折线构成,每条折线代表一个事件中这些属性的分布,而这些分布在一起又构成一个分布的分布。
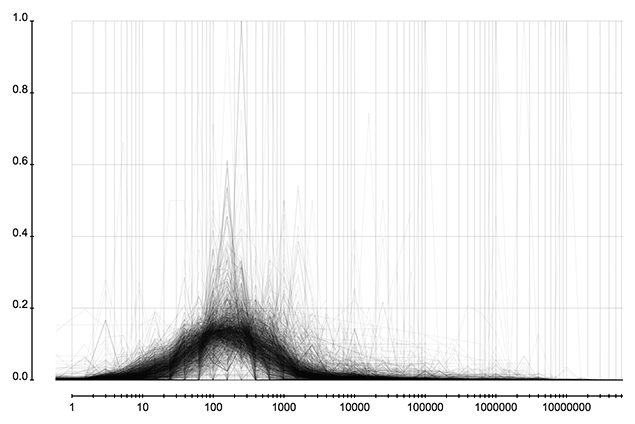
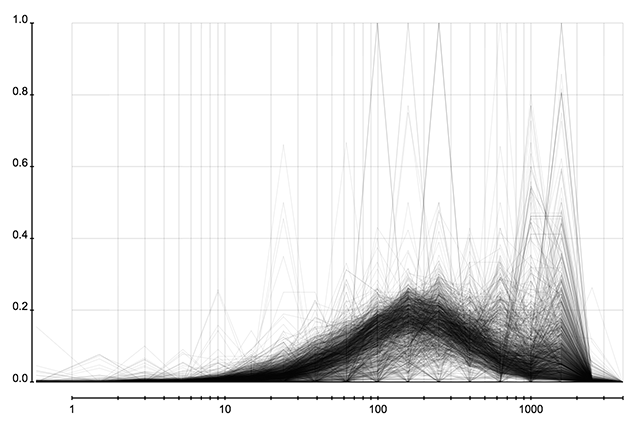
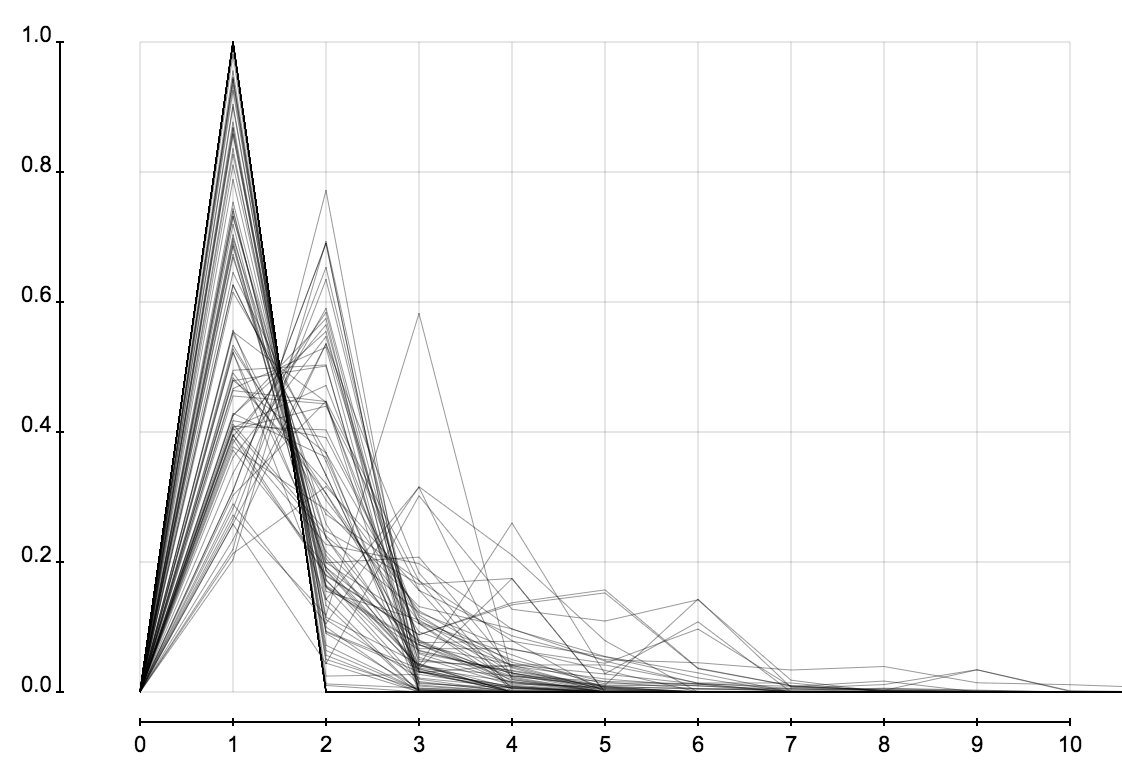
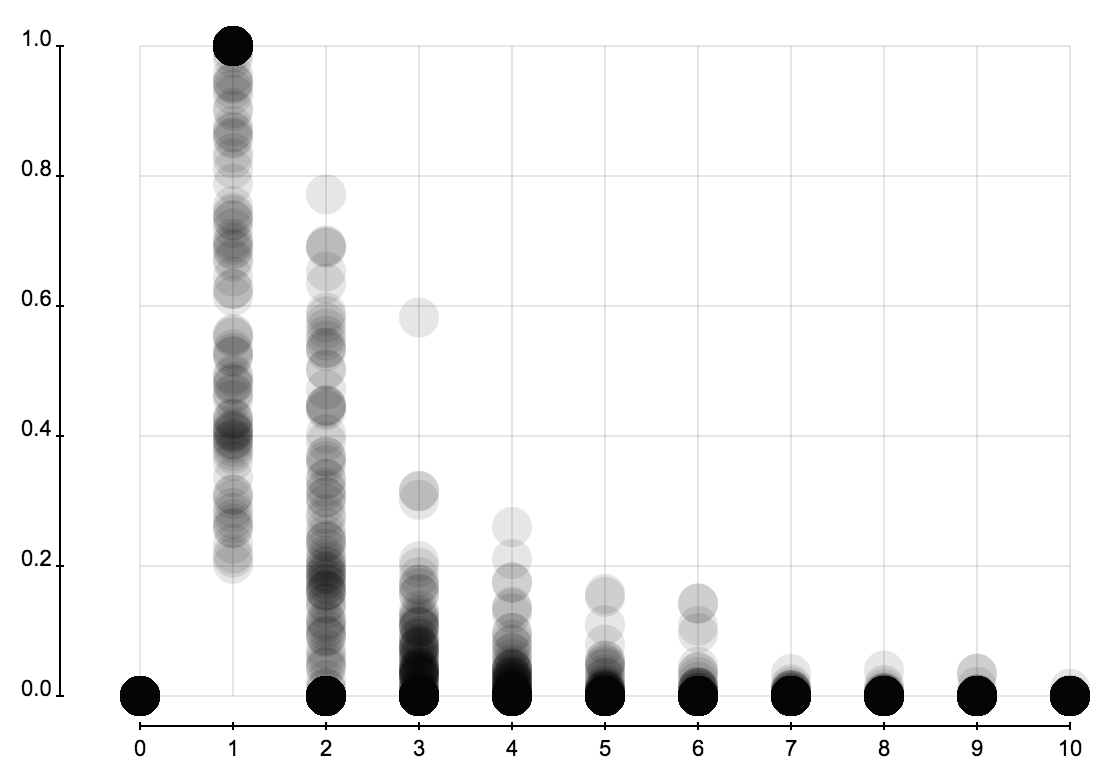
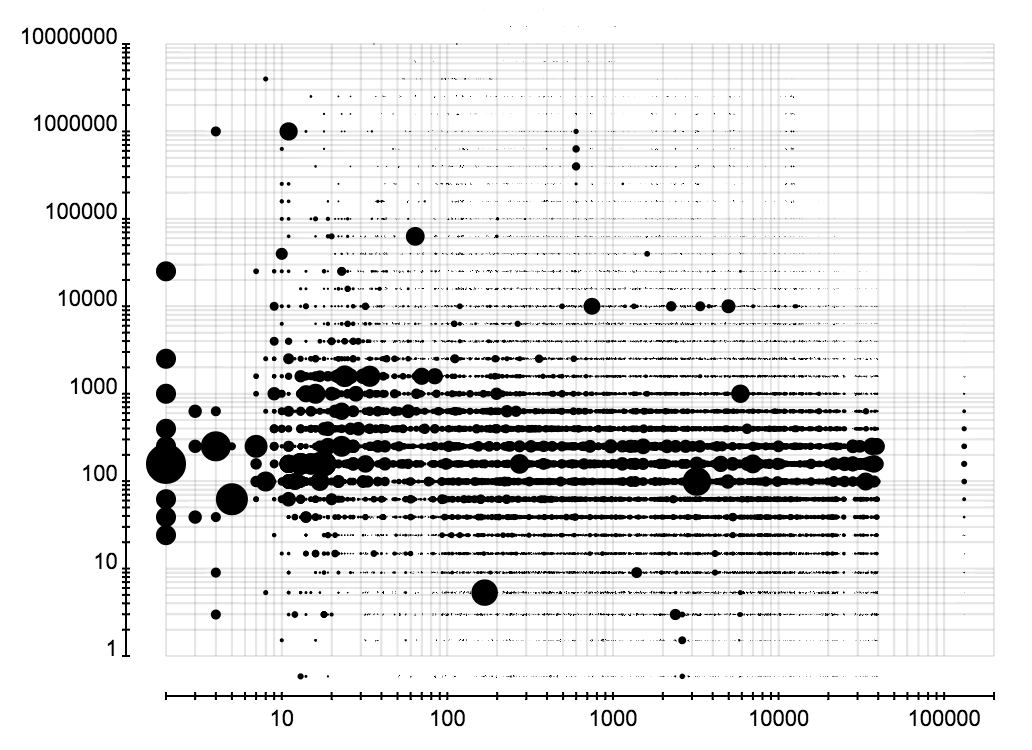
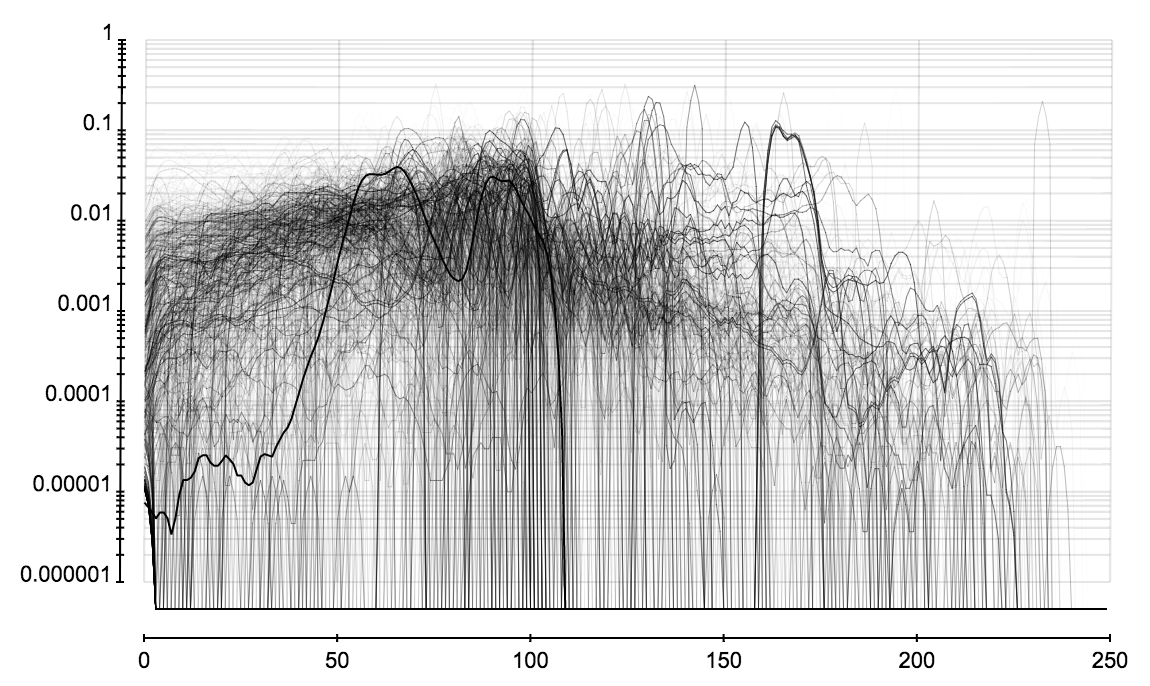
下面是对这些事件中分布的特征的统计。可以看出事件的大小和转发者的关注、粉丝数的分布关系不大。
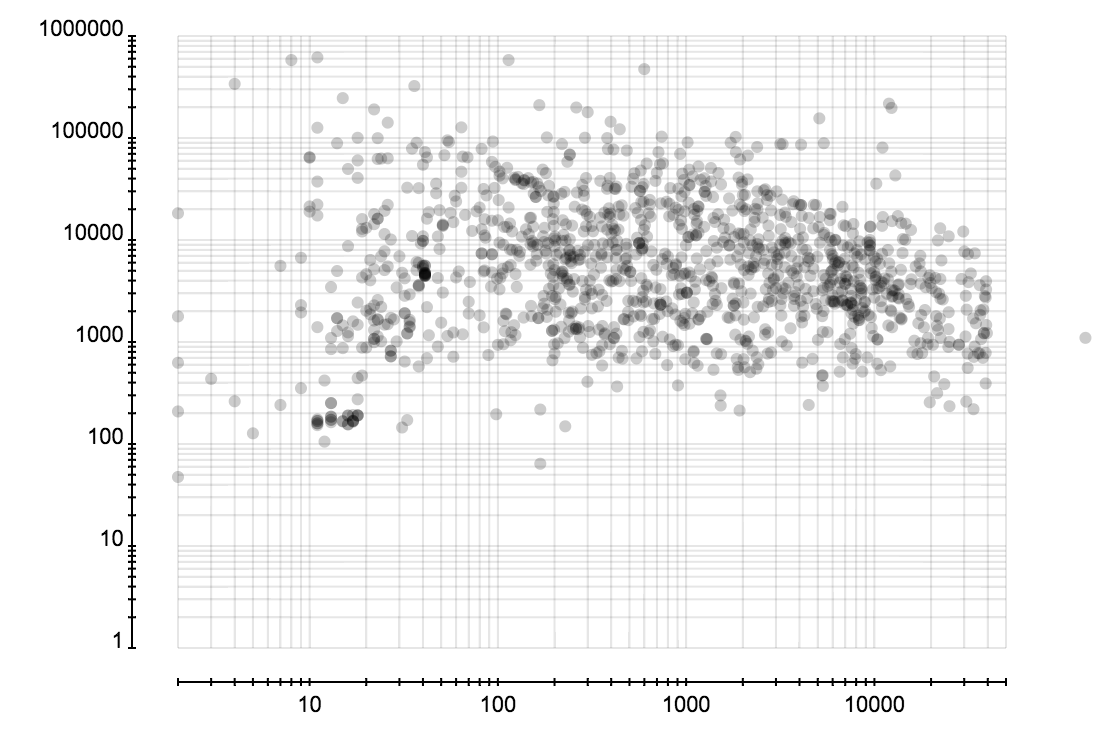
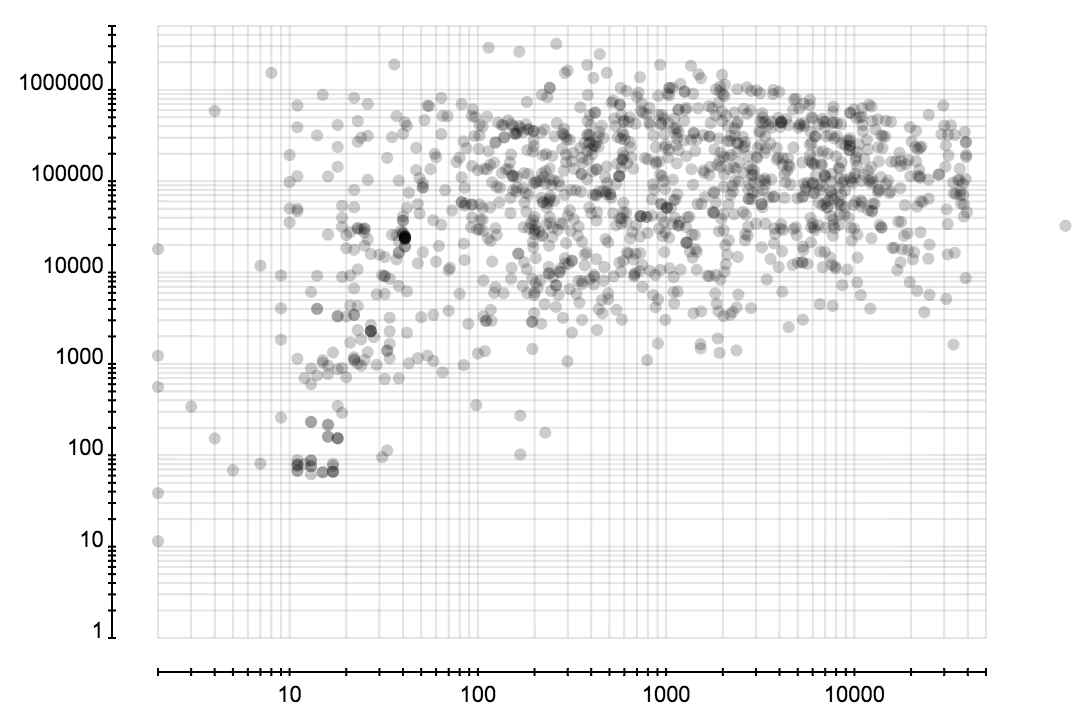
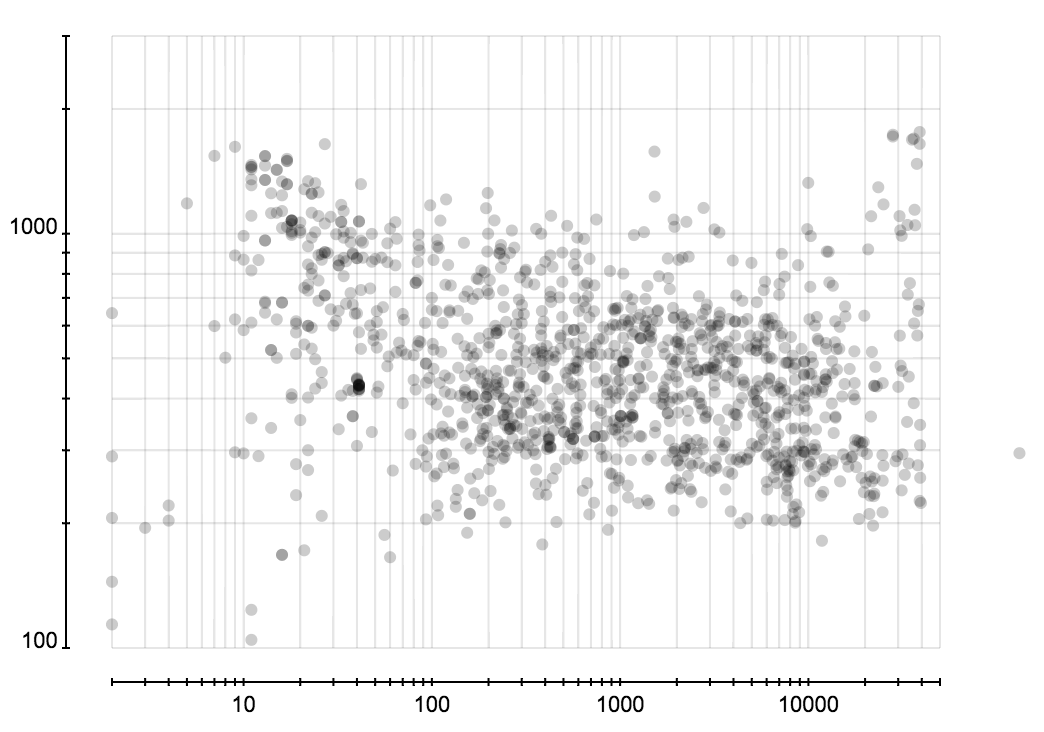
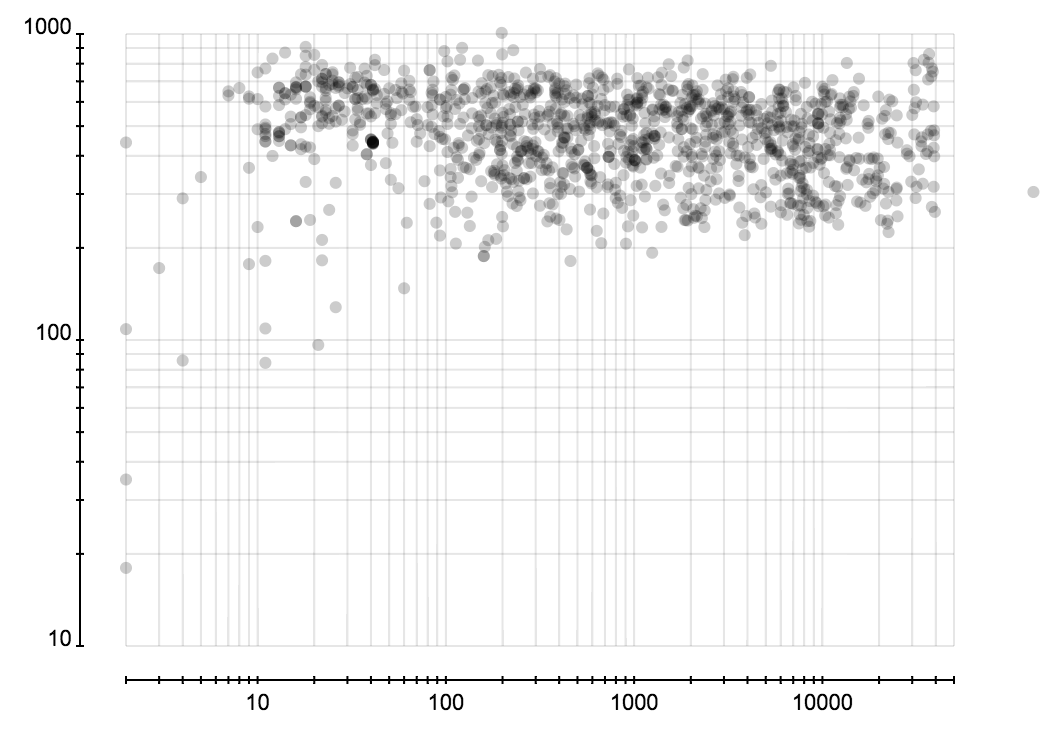
省份分布和城市分布可以很容易发现虚假账户,因为它们创建时都是随机选择省份和城市的,所以省份或成分的分布的熵会比正常的大很多。
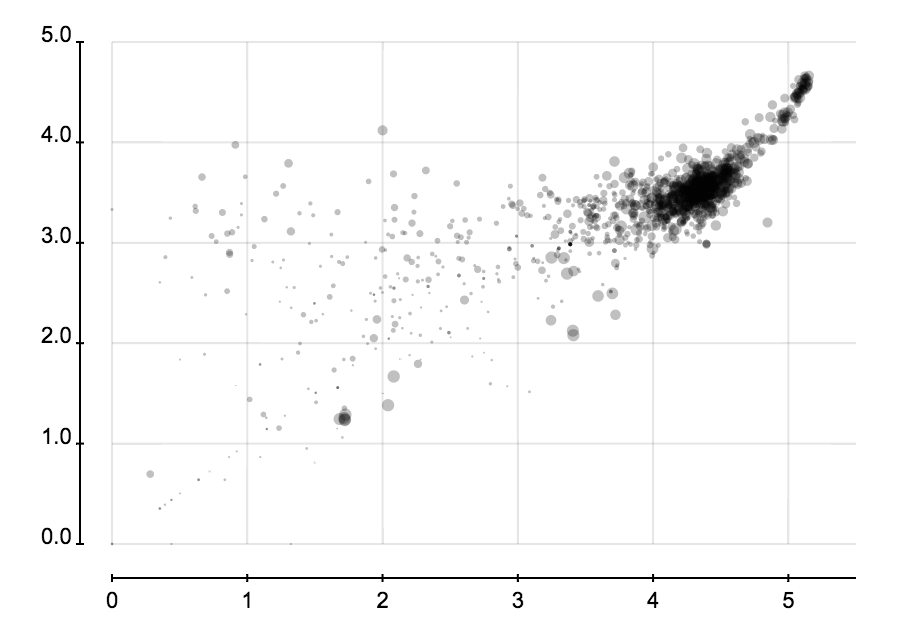
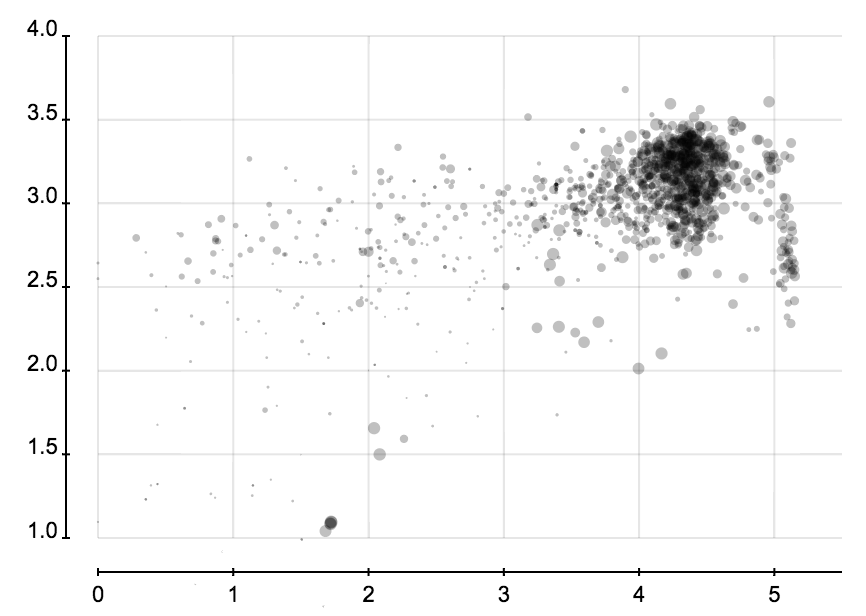
以上这些图都是用我的新项目 iVisDesigner 画的,过一段时间会发布它。
基于 HTML5 的可视化
近年来兴起的 HTML5 技术使得在浏览器中实现一些复杂应用成为可能。作为一个可视化应用,与传统的网站不同,关注点主要在绘图和界面与交互上。因为是刚开始学 HTML5 开发时写的,并一直延续至今,WeiboEvents 的代码比较混乱,混合了很多种不同的风格,其中的一些设计可能不是那么合理,下面是其中我认为值得一提的几点。
绘图
HTML5 提供了 Canvas 和 SVG 两种绘图方法,它们各有优劣。Canvas 是基于位图的,有一套绘图命令,就像常见的的绘图 API 那样,执行一个命令就绘制一个图元。而 SVG 则是基于 DOM 模型的,其中每个图元是一个 DOM 树上的一个节点,通过修改这些节点的属性,或者增减节点,可以完成绘图。 Canvas 的好处在于绘图效率比较高,SVG 的好处则是可以交互实现更方便。应该用哪种当然要由应用的性质来决定了。
WeiboEvents 中只使用了 Canvas。一方面是因为图中节点比较多(显示过的最大的微博数已经可以达到 100,000 条),另一方面是需要导出图片,这里用 Canvas 会更方便,因为 Canvas 中的图像可以直接输出成 PNG 格式。为了提高交互的效率,WeiboEvents 中用了多层的 Canvas。最底下的一层是节点和连接,往上一层显示鼠标指向的节点和高亮的节点,在上是用户添加的标注等。 这样的好处是当用户移动鼠标或者高亮节点的时候,不需要重新绘制所有点,只要把上面两层重绘即可。对于点很多的可视化来说效率提升是极大的。当然,这样做程序的逻辑就会比较复杂,因为要判断什么时候重绘整个图像,什么时候只需重绘一层。
界面与交互
HTML5 设计用户界面非常方便,只要用一些 div, span 等元素,结合 CSS 就可以轻松构建各种界面元素了。界面的编程主要用了 jQuery 和,在新版本中加入了绑定和事件的机制,让代码中的参数与界面元素的同步变得更方便了。
对于可视化中常见的点击、拖动等操作,这里大量采用异步和函数闭包的方式,例如鼠标拖动的实现:
// Start handling a dragging process.
beginDragging(function(x, y) {
// Mouse moving.
}, function(x, y) {
// Mouse up.
});这样的编程风格很适合界面交互的代码,很多参数不需要定义为全局变量,状态的保存和管理非常方便。Javascript 语言非常灵活,可以根据需要设计一些帮助函数,比如这里的 beginDragging,可以简化很多代码。核心的理念就是将常见的程序流程抽象出来,编写(或利用已有的)辅助框架,使得代码变得简洁。
节点的选中操作,需要查找鼠标位置对应的节点。逐一判断当然不是个好办法,一种常见的优化方法是用四叉树 (Quadtrees),不过在 WeiboEvents 里面用了更朴素的方法,就是建立一个像素到节点的索引,每个像素保存一下它上面有哪些节点。这样需要一个和像素数一样大的数组,比较占空间,但实现起来比四叉树简单些,效率也可以接受。
服务器端
WeiboEvents 的服务器端比较简单,主要就是可视化设计的保存与读取,以及访问日志的维护。是基于 PHP + MySQL 实现的。比较大的数据,比如用户上传的图片和微博数据,则存储在文件系统中,通过 hash 来命名并索引。
最近增加了一个后台任务的队列管理程序,用户可以在服务器上运行一些比较慢的任务,例如更深入的数据抓取。
数据获取
数据的获取就是通过新浪微博的 API。对于微博的转发树来说,只要调用 statuses/repost_timeline 接口即可。当然,其中会有很多问题,比如早期的接口不提供 pid 这个参数,因此无法直接得到微博的父节点,就需要递归地调用 repost_timeline 这个接口,很耗时间并且浪费请求数。从某个时间开始 pid 参数被加进来了,因此需要的请求数大幅度减少。但也只能得到最新的 2000 条转发。至于是怎么抓取到 13 万条转发的,那就只能说是秘密了。
数据可以在服务器端抓取,也可以在浏览器端抓取。为了减轻服务器的压力,最初的设计是数据抓取全部在浏览器端完成,并一直沿用下来。这样的问题是不够灵活,难以实现实时抓取数据和可视化。浏览器端抓取数据完全采用异步模式,也就是下面这种形式的调用。
// Call API
call_weibo_api(url, parameters, callback_function);当然不能一瞬间发送太多的请求,否则有一部分会超时,也很容易瞬间将请求数用尽。因此设计了一个请求队列,调用的方式还和上面一样,只是不会马上发送请求,要等前面的请求完成以后才发送。另外,错误的处理也很重要,有时微博 API 会不返回或返回无效的结果,也可能请求数量超过限制,这些都要正确处理,才能流畅地抓取数据。特别是对于 WeiboEvents 这样的分析型应用,需要的数据量比较大,需要连续很多次的抓取,因此这方面尤为重要。
小结
本文简述了 WeiboEvents 的设计与实现,以及一些关于事件的分析。希望对读者有所帮助。